游戏设计模式
中文地址游戏编程模式
作者在阅读了EA代码库和GoF的设计模式后针对游戏编程领域总结提炼出了更多的设计模式。其中传统的设计模式也会采用更偏向于游戏中的例子来列举,而不是银行职员之类偏生活化的例子。更适合游戏开发人员阅读。
架构、性能和游戏
什么是优秀的软件架构?
好的设计意味着当我做出改变时,整个程序就像是为了这一改变而精心打造的一样。我可以用几个恰到好处的函数调用解决问题,而不会在代码的平静表面上留下任何涟漪。
解耦有什么好处?
如果两段代码耦合在一起,那就意味着必须理解其中一段才能理解另一段。如果把它们之间解耦,就可以独立地对任何一方进行推理。这样的好处在于,如果只有其中一段跟我们的问题相关,就只需要把这一段加载大脑里,而无需加载另外一部分。 对我而言,这是软件架构的关键目标:在能够取得进展之前,尽量减少你需要在大脑中拥有的知识量。 解耦的另一个定义是,对一段代码的更改并不需要更改另一段代码。我们显然需要做出一些改变,但耦合度越低,这种改变对游戏其他部分的影响就越小。
那么代价呢?
但这正是事情变得棘手的地方。每当你在抽象层或支持扩展性的地方添加内容时,你就是在猜测你将来需要这种灵活性。你正在为你的游戏添加代码和复杂性,这需要时间来开发、调试和维护。 当人们对这变得过于热情时,你得到的代码库架构就会失控。到处都是接口和抽象,插件系统、抽象基类、虚拟方法以及各种扩展点比比皆是。 理论上,所有这些解耦意味着在扩展之前你需要理解更少的代码,但抽象层的本身最终填满了你的大脑。
性能和(开发)速度
软件架构和抽象有时会受到批评,尤其是在游戏开发中:它会影响游戏性能。许多使代码更灵活的模式都依赖于虚函数调用、接口、指针、消息和其他机制,这些机制都至少有一些运行时成本。 (对于性能和开发速度)没有一个简单的答案。使你的程序更加灵活以便更快地进行原型设计将会有一些性能损失。同样,优化你的代码将使其灵活性降低。 我的经验是,快速制作一个有趣的游戏比制作一个快速的游戏更有趣。一个折衷的办法是在设计稳定下来之前保持代码的灵活性,然后稍后移除一些抽象部分以提高性能。
坏代码的价值
原型设计——编写仅仅足够回答设计问题的代码——是一种完全合法的编程实践。然而有一个很大的前提。如果你编写的是一次性代码,你必须确保你能够将其丢弃。我见过一些糟糕的管理者一次又一次地玩这个游戏:(一开始花几天做出了一个原型,之后又要求只花几小时整理一下就当作成品) 您需要确保使用一次性代码的人明白,尽管它看起来好像能工作,但它无法维护并且必须重写。如果你可能不得不保留它,就可能需要做好防御性编程。
保持平衡
- 我们希望有好的架构,这样代码在整个项目生命周期中更容易理解。
- 我们希望运行时性能快速。
- 我们希望快速完成今天的特性。 这些都是关于某种速度:我们的长期开发速度、游戏的执行速度以及我们的短期开发速度。 同样没有简单的答案,只有权衡取舍。“没有正确答案,只有不同形式的错误”可能会让很多人感到沮丧。 对我来说,这与游戏本身有很多共同之处。像棋类游戏这样的游戏永远无法精通,因为所有的棋子都完美地相互制衡。这意味着你可以花费一生的时间探索可行策略的广阔空间。(相反地)一款设计糟糕的游戏会沦为某种可重复使用的获胜策略,你最终会感到厌倦并退出游戏。
简洁
最近,我觉得如果有什么方法可以减轻这些限制,那就是简洁性。在我的代码中,我非常努力地编写最干净、最直接的问题解决方案。这种代码在你阅读后,能立刻明白它的作用,并且无法想象其他可能的解决方案。 然而,我并不是说简单的代码写起来更省时间。你会以为是这样,因为你最终写出的代码更少,但一个好的解决方案并不是代码的累加,而是对代码的提炼。
But, most of all, if you want to make something fun, have fun making it. 但最重要的是,如果你想做出有趣的东西,就要享受制作它的过程。
设计模式再探(Design Patterns Revisited)
命令(Command)
A command is a reified method call. 命令是一个具体化的方法调用。 Another term for reifying is making something “first-class” 具体化的另一个说法是使某物成为“一等”。 将某个概念转化为可以放入变量、传递给函数等的数据——一个对象。所以当我提到命令模式是一个“具体化的方法调用”时,我的意思是它是一个封装在对象中的方法调用。 这听起来很像“回调”、“一等函数”、“函数指针”、“闭包”或“部分应用函数”,这取决于你来自哪种语言。
输入处理
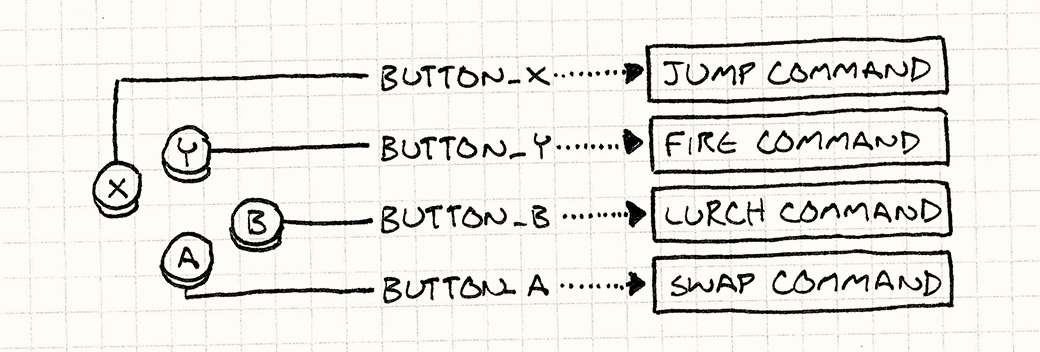
命令可以序列化,然后就可以通过网络发送给其他玩家,这就是网络多人游戏的重要组成部分。
撤销和重做
当玩家选择“撤销”时,我们将撤销当前命令并将当前指针回退。当玩家选择“重做”时,我们将指针向前移动并执行该命令。如果他们在撤销一些操作后选择新的命令,则当前命令之后列表中的所有内容将被丢弃。
优雅的实现
如果你有幸使用支持真正闭包的语言,那就尽情使用吧!在某种程度上,命令模式是模仿没有闭包的语言中的闭包的一种方式。
享元(Flyweight)

把共享的不可变对象放到同一块内存中复用,而不是单独保存多份。
观察者(Observer)
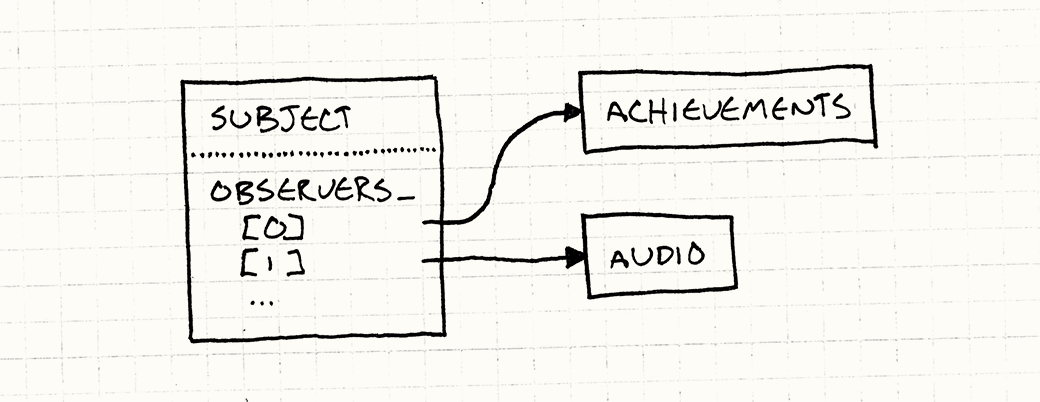
可观察的主题(Subject)维护着一个观察者数组,可以添加、删除、遍历通知观察者。也可以维护一个双向链表,可以在常数时间内执行添加删除。需要注意主题和观察者的销毁行为。
如果我现在设计一个观察者系统,我会让它基于函数而不是基于类。即使在 C++中,我也倾向于一个允许你将成员函数指针注册为观察者的系统,而不是某些 Observer 接口的实例。 许多最近的应用框架现在使用“数据绑定”。 与更激进的模型不同,数据绑定并非试图完全消除命令式代码,也不会试图将整个应用程序构建在一个巨大的声明式数据流图中。它所做的只是自动化那些需要调整 UI 元素或计算属性以反映某些值变化的工作。 就像其他声明式系统一样,数据绑定可能有点慢且复杂,不适合放在游戏引擎的核心部分。但如果它没有用在游戏中不那么关键的领域,比如 UI,我会感到很惊讶。
原型(Prototype)
让子对象实现Clone接口,或者通过JSON来做序列化和反序列化
单例(Singleton)
这本书中的其他章节都向你展示了如何使用设计模式。而这一章节则向你展示了如何不使用它。
- 单例的作用
- 确保类只有一个实例和
- 提供一个全局访问点
- 使用单例的好处
- 没人使用时可以不创建实例
- 可以在运行时初始化。如果是静态类的话将不能获取运行时才有的信息
- 可以被继承以实现多态。比如
instance()函数中可以根据当前平台创建对应的实例。
- 单例的问题 这是一个全局变量,而全局变量有很多坏处
- 它们使得对代码进行推理变得更加困难。比如说,我们要追踪别人编写的函数中的错误。如果那个函数没有触及任何全局状态,我们只需要理解函数体和传递给它的参数,就能理解这个函数。想象在其中有一个
SomeClass::getSomeGlobalData()的调用,为了弄清楚发生了什么,我们必须在整个代码库中搜索,看看什么操作了那个全局数据。你可能不会真的讨厌全局状态,除非你曾不得不在凌晨三点grep一百万行代码来试图找到那个将静态变量设置为错误值的调用。 - 它们鼓励耦合。假如团队有个新人,他的第一个任务是在石头撞击地面时发出声音。你和我知道不想让物理和音频耦合,但是他也只是想完成他的任务。不幸的是,我们有一个全局可见的
AudioPlayer实例,他只要加一个小小的include就破坏了“精心设计”的架构。假如没有这样的全局实例,就算他引入了一个头文件也做不了什么事情。这种困难向他传达了一个明确的信息,即这两个模块不应该相互了解,他需要找到另一种方法来解决他的问题。通过控制实例的访问,你控制了耦合。 - 对于多线程不友好。竞争条件、死锁和其他难以修复的线程同步bug。
- 是否真的需要单例
- 对于游戏中存在的各种管理器,如果管理器只是用来提供辅助函数,那么完全可以把这些函数放入到需要的类中。
- 对于限制类只有一个实例,可以在构造函数添加断言,当然这样只能在运行时做限制。
- 对于便捷访问,有时候并不一定需要这么大的作用域,我们一般希望变量作用域的范围尽可能小。
- 传递。是最简单也是通常情况下最好的解决方案。就是直接将所需的对象作为参数传递给需要它的函数。
*
有些人用“依赖注入”这个术语来指代这个。不是代码通过调用全局对象来寻找其依赖,而是通过参数将依赖推入需要它的代码中。
*
但是有些对象不适合作为方法签名的一部分,比如
Log。对于这种情况我们应该考虑其他办法,比如面向切片编程 - 从基类获取。例如有一个
GameObject基类,可以直接获取基类的Log对象。- 除了基类外,没有任何东西可以访问其
Log对象。这种让派生对象根据提供给它们的受保护方法自行实现自己的模式,在子类沙盒章节中有详细说明。
- 除了基类外,没有任何东西可以访问其
- 从已经全局化的东西中获取。大多数代码库仍然会有一些全局可用的对象,例如代表整个游戏状态的单个
Game或World对象。这些单例中保存了诸如Log之类的静态实例。- 纯粹主义者会声称这违反了 Demeter 法则。我认为这仍然比一大堆单例要好。
- 如果后来架构被修改以支持多个
Game实例(可能是为了流式传输或测试目的),这些Log都不会受到影响。当然,这种做法的缺点是,更多的代码最终会与Game本身耦合。
- 从服务定位器获取。它本身也是一个全局类,但是它唯一存在的理由就是提供对对象的全局访问,这种常见的模式被称为服务定位器(Service Locator)。
状态(State)
那些年我们写过的代码
那些你崇拜的程序员,他们似乎总是能写出无懈可击的代码,并不是因为他们是超人级的程序员。相反,他们对哪些类型的代码容易出错有直觉,并避开这些代码。 复杂分支和可变状态——随时间变化的字段——是那些容易出错的代码类型之一,上述示例都包含这两种。
有限状态机
你为女主角能做的每一件事画一个框:站立、跳跃、蹲下和潜水。当她处于这些状态之一时,可以响应按钮按压,你就从那个框画一条箭头,用那个按钮标记它,并将其连接到她改变到的状态。
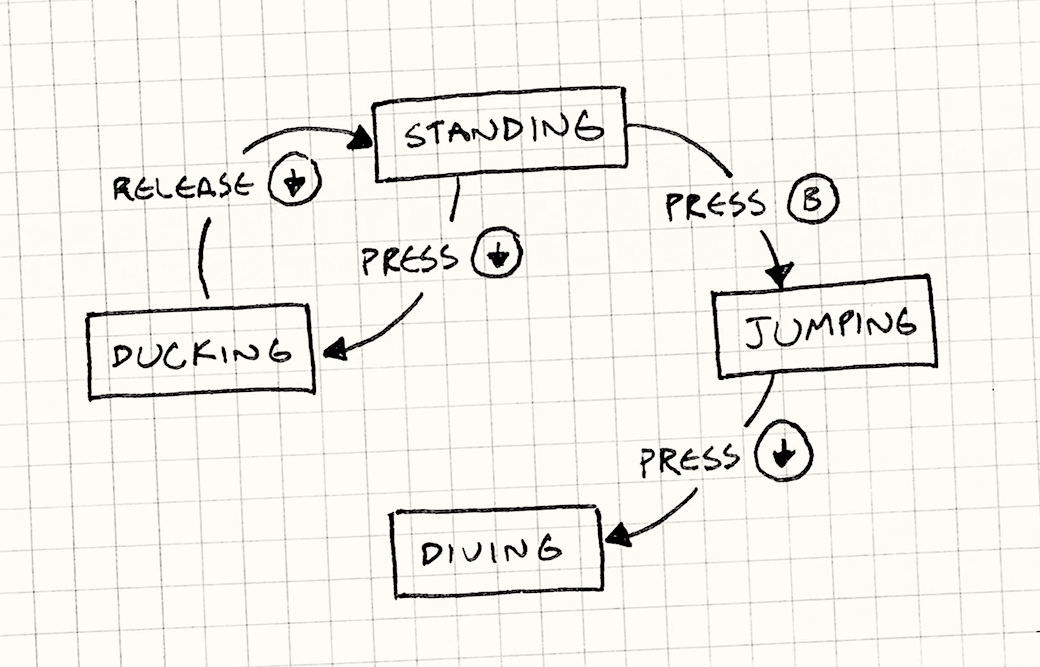
恭喜你,你刚刚创建了一个有限状态机。这些来自计算机科学的一个分支,称为自动机理论,其数据结构家族还包括著名的图灵机。FSM 是这个家族中最简单的成员。
核心内容: * 机器处于一个固定的状态集合 * 机器一次只能处于一个状态 * 有一系列输入或事件被发送到机器 * 每个状态都有一组转换
状态模式
首先,定义一个状态接口,之前switch中的各种行为都转变为了接口中的虚拟方法handleInput和update。
接着,对于每个状态,都要定义一个实现该接口的类。switch中的每个cast都可以移到对应状态类里。
接下来,记录一个当前状态的指针,并调用当前状态的接口。
状态的实例化,可以由状态类返回一个新的状态类
进入和离开的动作,对于状态类来说,需要在状态变化的时候执行一些代码
状态机的限制
有限状态机并不是图灵完备的。图灵完备意味着一个系统(通常是编程语言)强大到足以在其中实现图灵机,而图灵机是自动机理论中表达力最强的抽象模型,也就意味着所有图灵完备的语言在某种程度上都有同等的表达能力。但有限状态机不够灵活,无法纳入其中。 如果你尝试使用状态机来处理更复杂的任务,比如游戏 AI,你将直面该模型的上限。幸运的是,我们的前辈们找到了绕过一些障碍的方法。
并发状态机(Concurrent State Machines)
假如让女主角可以在跑跳同时还可以开火,状态数量将会翻倍。我们为携带的武器定义一个单独的状态机。
需要注意的是: * 一个状态机消费了输入后可能就不能让另一个消费 * 当状态之间无关时效果很好,但如果相互之间有制约,比如跳跃时无法开火,可能还需要在一个状态里判断另一个状态机的状态,并不是很优雅
分层状态机(Hierarchical State Machines)
一个状态可以有一个父状态(使其成为子状态)。当事件到来时,如果子状态没有处理它,就会向上滚到父状态链。换句话说,它的工作方式就像覆盖继承的方法一样。
当然还可以使用状态栈显式模拟当前状态的超级状态链,而不是在主类中使用单个状态。 当前状态是栈顶的状态,下面是它的直接超状态,然后是那个状态的超状态,依此类推。
下推自动机(Pushdown Automata)
问题在于有限状态机没有历史概念。你知道自己处于哪个状态,但没有记忆自己之前处于哪个状态。没有简单的方法回到之前的状态。 (比如女英雄有个新的射击状态)困难的部分是她射击后过渡到哪个状态。她可以在站立、奔跑、跳跃和蹲下时开一梭子。当射击序列完成后,她应该回到之前的状态。 如果仍然使用普通的FSM,可能需要定义站立时开火、奔跑时开火等状态,以便完成时回到正确的状态。
而在下推自动机中,新状态不会直接替换掉上一个状态,而是提供了两个额外的操作: 1. 您可以向栈中推入一个新的状态。当前状态始终是栈顶的状态,因此这会过渡到新状态。但它将先前的状态直接放在其下方,而不是丢弃它。 2. 您可以弹出栈顶的状态。该状态被丢弃,其下的状态成为新的当前状态。
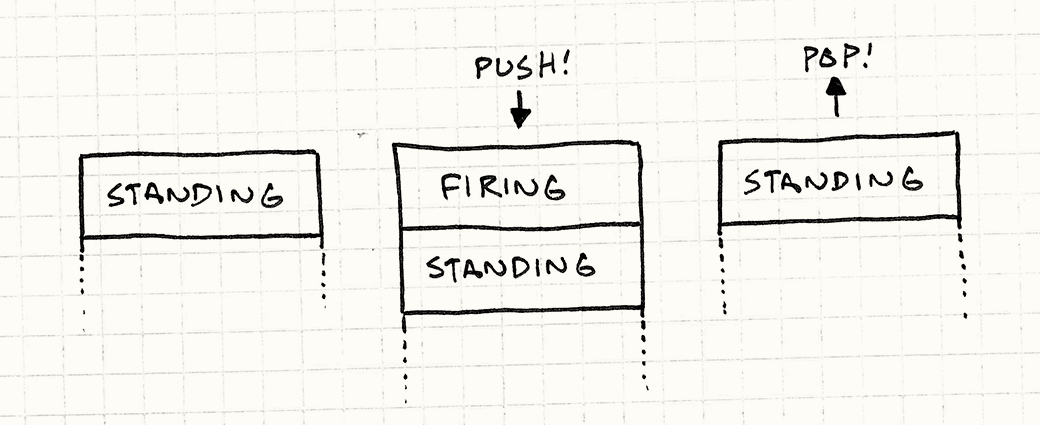
当在任意其他状态下按下点火按钮时,我们将发射状态推入栈中。当点火动画完成后,我们弹出该状态,下压自动机将回到我们之前的状态。
实际应用
如今游戏 AI 的趋势更倾向于像行为树(behavior trees)和规划系统(planning systems)这样的令人兴奋的事物。
但是有限状态机、下推自动机以下情况仍然有用: 1. 一个实体的行为基于内部状态而改变 2. 该状态可以严格划分为相对较少的几种 3. 实体会随时间对一系列输入和事件做出响应
除了AI,也常用于用户输入处理、导航菜单屏幕、解析文本、网络协议和其他异步行为的实现中。
关于C#异步状态机的实现
参考这篇文章的反编译分析,每个异步方法都会编译成一个状态机,根据执行状态state结合goto跳转到对应的代码行。
序列模式(Sequencing Patterns)
双缓冲(Double Buffer)
意图:使一系列顺序操作看起来像是即时或同时发生。 双缓冲解决的核心问题是状态在被修改时被访问。(比如正在更新一个数组的过程中某个地方要访问数组,这时访问到的数据就可能是不对的,使用双缓冲,会多保存一个数组,在修改过程中访问的是上一次的完整数组,至少在上次是完整而且正确的)
游戏循环(Game Loop)
意图:将游戏时间的推进与用户输入和处理器速度脱钩。(这里说的是类似于Unity中的Update和FixedUpdate,Update中乘以deltaTime来弥补帧率抖动,而物理世界中的模拟需要以固定帧率步进,在FixedUpdate中进行)
更新方法(Update Method)
意图:通过让每个对象一次处理一帧的行为来模拟一组独立的对象。 游戏世界维护一个对象集合。每个对象实现一个更新方法,模拟对象的一个行为帧。每帧,游戏更新集合中的每个对象。
需要小心在遍历的过程中发生了添加和删除的情况。如果只会添加,只需要记录当前帧需要遍历的数量;如果会删除,应该在这一帧标记,全部遍历完后才执行真正的删除。
行为模式(Behavioral Patterns)
字节码(Bytecode)
意图:通过将行为编码为虚拟机的指令,赋予行为数据灵活性。(这里讲的是脚本系统) 即使你最终没有使用这个模式,你至少对 Lua 和许多使用它实现的其它语言有了更好的理解。 这是本书中最复杂的模式,而且它不是可以轻易地扔进你的游戏中的东西。当你有很多需要定义的行为,并且你的游戏实现语言不适合时使用它: 1. 太底层了,编程繁琐或容易出错。 2. 由于编译时间慢或其他工具问题,迭代它需要太长时间。 3. 它太过于信任了。如果你想确保定义的行为不会破坏游戏,你需要将它与代码库的其他部分隔离开来。
- 指令集,执行时switch字节码枚举进入真正的代码,字节码只需要一个字节即可。
- 堆栈机(stack machine),可以push和pop栈中的值。
两种虚拟机
- 基于栈的虚拟机(stack-based VM)总是从栈顶开始工作
- 指令很小。每条指令隐式地在栈顶获取参数。
- 代码生成更简单。
- 需要更多指令。比如
a=b+c需要指令分别将b和c移动到栈顶,执行操作,然后移入a。
- 基于寄存器的虚拟机(register-base
VM)也有栈,但是可以直接读取栈中指定位置的数据
- 指令更大。指令需要包含栈偏移的参数,一个指令也就需要更多的位数。比如Lua中的指令有32位,其中6为表示类型,其余的是参数。
- 指令更少。因为一条指令可以做更多工作,所以不需要太多。而且因为不需要频繁在栈中移动值,性能可能更好一点。
我的建议是坚持使用基于栈的虚拟机。它们实现起来更简单,生成代码也更容易。(虽然Lua是基于寄存器的)
值的表示
- 单一数据类型(single datatype)
- 很简单,但是无法处理不同的数据类型
- 一个标记变体(tagged variant)
- 这是动态类型语言的常见表示
- 每个值有两个部分:类型标签和不同类型值的union
- 未标记的联合体(untagged union)
- 这是静态类型语言在内存中表示事物的方式
- 非常紧凑、快速,但是也不安全,可能会误解一个值,导致游戏崩溃
- 一个接口
- 使用面向对象来解决,每种特定的数据类型都实现对应的具体类,包含类型转换和类型标识
- 可扩展、面向对象,但是很繁琐,需要定义类型,而且效率低下
我的建议是,要么坚持使用单一数据类型,要么使用带标签的联合体。世界上几乎每种语言解释器都是这样做的。
字节码的生成
- 如果定义的是基于文本的语言
- 要定义语法、解析器、处理语法错误
- 对于非技术人员不友好
- 如果定义的是图形化创作工具
- 要实现一个用户界面、更不容易出错
- 可移植性差(指的是跨平台的UI工具)
这种模式与四人帮的解释器模式非常相似。两者都提供了一种以数据方式表达可组合行为的方法。
作者的小脚本语言Wren
子类沙盒
意图:使用基类提供的一系列操作在子类中定义行为。 模式:一个基类定义了一个抽象的沙盒方法以及一些提供操作。将它们标记为受保护使得它们明确是为派生类使用的。每个派生的沙盒子类使用提供操作来实现沙盒方法。
何时使用 * 有一个基类和多个派生类 * 基类能够提供派生类可能需要执行的所有操作 * 子类之间存在重复的行为,希望可以复用代码 * 希望最小化这些派生类与程序其他部分的耦合
类型对象(Type Object)
意图:通过创建一个类,允许灵活地创建新的“类”,每个实例都代表一种不同类型的对象。
(实际指的是,当对象只是数据不同时,不需要分别创建子类,只需要将数据部分单独抽出来,用一个数据类保存即可)
解耦模式(Decoupling Patterns)
当我们说两段代码是“解耦”时,我们指的是对一个的改变通常不需要对另一个的改变。
组件
意图:允许单个实体跨越多个领域(domains),而不将域耦合在一起。 一个实体跨越多个领域。为了保持领域的隔离,每个领域的代码都放置在它自己的组件类中。实体被简化为一个简单的组件容器。
组件之间的通信方式 1. 直接修改容器对象的状态。但是过多的共享可变状态很容易出问题 2. 直接相互引用,存在紧密耦合 3. 发送消息,完全解耦
不足为奇,这里没有唯一的最佳答案。
事件队列
意图:将消息或事件的发送和处理进行解耦。 队列以先进先出的顺序存储一系列通知或请求。发送通知会将请求入队并返回。请求处理器随后会在稍后时间从队列中处理项目。请求可以直接处理或路由到相关方。这既在静态上又在时间上解耦了发送者和接收者。(事件发出后并不立即处理,而是在其他时间点处理,比如可以做消息合并、延后执行,避免阻塞发送方,也即在时间上解耦)
这是观察者模式的异步版
服务定位器
意图:提供一个全局访问点以获取服务,而不将用户耦合到实现它的具体类。 服务定位器模式的核心——它将需要服务的代码与其具体实现类型以及获取其实例的方式解耦。
服务定位的方式 1. 外部代码注册 2.
编译时绑定(用#if判断决定) 3. 在运行时配置
服务无法定位时的处理 1. 让调用方处理 2. 断言,中断游戏 3. 返回空服务(null service),这是一种空对象模式
服务定位还可以限制在类中,类似于Unity中的GetComponent,传入接口类型,直接上也是一种服务定位器。
优化模式(Optimization Patterns)
数据局部性(Data Locality)
意图:通过排列数据以利用 CPU 缓存来加速内存访问。 模式:现代 CPU 有缓存来加速内存访问。这些可以更快地访问最近访问过的内存相邻内存。利用这一点来通过增加数据局部性来提高性能——将数据保持在按您处理顺序的连续内存中。 像大多数优化一样,使用数据局部性模式的第一条指导原则是在你遇到性能问题时。不要浪费时间将这个模式应用到代码库中不常执行的某个角落。优化不需要优化的代码只会让事情变得更复杂,更不灵活。 对于这个模式,你还需要确保你的性能问题是由缓存未命中引起的。如果你的代码因为其他原因而慢,这不会有所帮助。
实例 1. 用数据保存连续数据(对于结构体只能保存相同类型的数据到同一个数据) 2. 打包数据,把需要遍历的和不需要遍历的分开存储,而不是遍历时才去判断 3. 冷热分离(Hot/cold splitting),把使用不频繁的数据单独保存。(但一般情况下不好判断)
脏标记(Dirty Flag)
意图:通过推迟工作,直到需要结果时再进行,以避免不必要的工作。
比如变换矩阵发生改变,并不立即计算,而是延迟到渲染之前才计算,可以避免中间改变会导致的无效计算
清理标记的时机 1. 在需要结果的时候 2. 在明确定义的检查点 3. 在后台定时计算
同时还要衡量标记的粒度,也是内存和时间的权衡
对象池(Object Pool)
意图:通过重用固定池中的对象来提高性能和内存使用,而不是单独分配和释放它们。
适用场景 1. 需要频繁地创建和销毁对象 2. 对象地大小相似 3. 堆上分配对象比较慢,或者可能导致内存碎片化 4. 每个对象封装了一个资源,比如数据库或网络连接,这些资源获取成本高昂并且可以重复使用
对于池子的尺寸上限问题 1. 直接调整大小,可能会因为少数情况的峰值导致创建大量对象。可以考虑为每种场景调整池大小。 2. 不创建新对象了,用对象池大小指代同时可激活的上限 3. 强制杀死一个现有对象 4. 考虑额外容量不再需要时,池是否应该收缩到之前的大小
要特别注意池中初始化新对象的代码必须完全初始化对象。甚至值得花点时间添加一个调试功能,在对象被回收时清除对象槽的内存。
空间划分(Spatial Partition)
意图:通过将对象存储在按其位置组织的结构中来高效定位对象。 模式:对于一组对象,每个对象在空间中都有一个位置。将它们存储在一个按它们位置组织的空间数据库结构中。这种数据库结构允许你有效地查询位于或靠近某个位置的对象。当对象的位置发生变化时,更新空间数据库结构,以便它能够继续找到该对象。
文章避免详细讨论具体的空间划分结构,推荐学习: 1. Grid,桶排序的思想,给定坐标即可快速划分到对应区域 2. BSP、k-d tree、Bounding volume hierarchy,都是二叉搜索树 3. Quadtree、octree,字典树的思想,利用前缀(父节点)来快速剪枝